HBM(고대역 메모리) 이란? 인공지능의 연산을 높이는 D램
HBM은 현재까지 존재하는 메모리 칩 기술에 비해 훨씬 더 빠르면서 전기 소비량은 더 적고 공간도 더 적게 차지한다. Chat GPT를 시작으로 생성형 인공지능(AI) 시장이 급성장하면서 AI 서버 개발을 위한 HBM이 IT 업계에서 주목을 받고 있다.

이번 포스팅과 함께 보면 좋은 HBM 관련주에 대해 알고 싶으시면 아래 링크를 확인해 주시기 바랍니다.
SK 하이닉스, 삼성전자 HBM 공급 경쟁, HBM 관련주 TOP 10
SK 하이닉스, 삼성전자 HBM 공급 경쟁, HBM 관련주 TOP 10
AI(인공지능) 열풍에 동반 상승하는 엔비디아의 GPU, 여기에 빠질 수 없는 메모리가 바로 HBM이다. 현재는 SK하이닉스가 유일하게 HBM3를 양산하고 있으며 엔비디아에 공급하고 있다. 삼성전자 또한
liar-fortune-teller.tistory.com
HBM(High Bandwidth Memory) 이란?
HBM(High Bandwidth Memory)은 한국어로 '고대역폭 메모리'란 뜻이다. 여기서 대역폭은 데이터를 전송 속도를 뜻하며, 고대역폭이라는 것은 데이터를 빠르게 전송한다는 의미이다. 즉 HBM은 데이터를 빨리 전송할 수 있는 메모리란 뜻이다.
HBM은 여러 개의 D램을 수직으로 연결해 기존 D램보다 데이터 처리 속도를 혁신적으로 끌어올려 고성능 컴퓨팅을 요구하는 생성형 AI에 필수적인 고성능 메모리 반도체이다.
메모리 구매자가 가장 중요하게 생각하는 메모리의 특성은 대역폭(Bandwidth), 반응속도(Latency), 용량(Capacity)이다. HBM은 이중 대역폭과 용량에 중점을 두었으며, 반응 속도를 다소 양보한 메모리이다. 여기서 대역폭은 한 번에 빼낼 수 있는 데이터의 양이며, 반응속도는 CPU/GPU의 명령에 얼마나 빨리 반응하는가 이고, 용량은 말 그대로 메모리 안에 데이터를 담을 수 있는 양을 뜻한다.
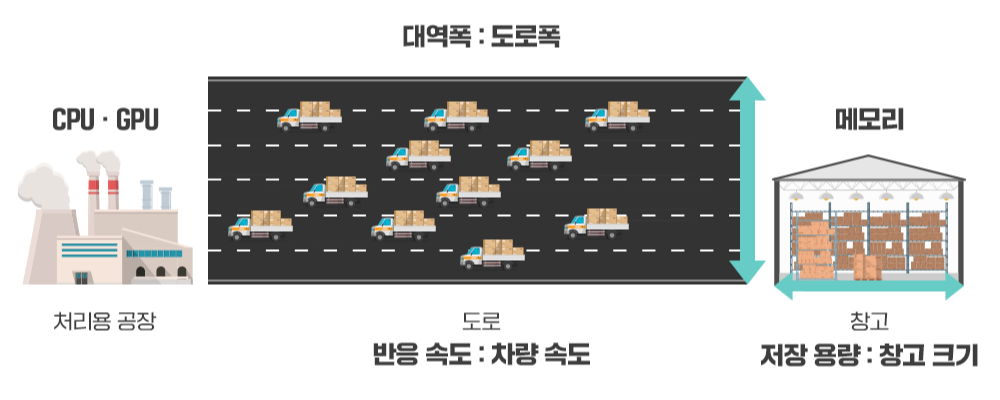
HBM은 D램을 여러 개 적층했기 때문에 높은 용량을 확보할 수 있으며, TSV 공법을 이용해 여러 D램의 데이터 연결 통로를 밀집시켜서 메모리 4개 이상의 대역폭을 갖고 있다. 하지만 칩을 적층 한 이유로 발열 해소에 문제가 생길 수 있어 개별 칩의 속도가 줄어들어 반응 속도에서 약간의 손해가 발생한다.
고성능 메모리 반도체인 HBM의 개발 연혁은 다음과 같다.
| 구 분 | 개발 연혁 |
| HBM1 (1세대) | 2013년 SK하이닉스 세계 최초 개발 |
| HBM2 (2세대) | 2015년 10월 삼성전자 첫 개발 / 2016년 1월 양산 |
| HBM2E (3세대) | 2020년 2월 삼성전자 첫 개발 |
| HBM3 (4세대) | 2021년 10월 SK하이닉스 첫 개발 / 2022년 6월 양산 |
| HBM3E (5세대) | 2023년 하반기 SK하이닉스 샘플 개발 / 2024년 양산 예정 |
HBM은 SK하이닉스가 2013년 세계 최초로 개발하였지만 삼성전자가 HBM 2, 3세대 제품인 HBM2, HBM2E 제품에서 앞서나갔다. 하지만 4세대 제품인 HBM3부터는 다시 SK하이닉스가 먼저 양산에 성공하면서 다시 선두 자리를 탈환하였다. 최근 양사는 HBM3E와 HBM4 등 본격적인 기술 경쟁을 벌이고 있다.
AI와 GPU
CPU는 컴퓨터의 두뇌이다. 한때 사람들이 컴퓨팅 파워에 대해 논할때 어떤 CPU(중앙처리장치)를 쓰고 있는지에 따라 컴퓨터의 성능이 좋다, 나쁘다 라고 평가한 적이 있었다. 하지만 AI에서 컴퓨팅 파워를 구분하는 기준으로 GPU(그래픽처리장치)를 더 많이 언급하고 있다.
GPU는 원래 CPU의 작은 부분이었다. GPU는 이름 그대로 PC 또는 컴퓨터 그래픽 및 비디오를 활성화하기 위해 보조적인 역할을 했다. 그러나 기술의 발전과 함께 GPU의 역할이 더욱더 중요해졌다. GPU는 병렬 처리 방식에 특화된 구조를 갖고 있어 시간이 오래 걸리는 영상이나 랜더링 등 고성능 그래픽 작업과 반복, 전문적인 컴퓨팅 작업을 빠르게 수행할 수 있다.

그럼 GPU가 단순한 그래픽 카드에서 AI에 쓰이는 고성능 켬퓨팅용 GPU로 발전한 계기는 무엇일까? 2000년대 컴퓨터 공학자들은 GPU가 일반 칩에서는 불가능한 수학 연산을 할 수 있는 것을 발견했다. 이른바 가속 컴퓨팅(Accelerated Computing)이다.
가속 컴퓨팅의 확정성에 주목한 엔비디아의 창업자 젠슨 황은 GPU가 가속 컴퓨팅을 더 효율적으로 할 수 있도록 도와주는 도구인 '쿠다(CUDA)'를 출시했다. 엔비디아의 GPU가 그래픽용에서 고성능 컴퓨팅용으로 진화하는 순간이었다. 쿠다는 많은 연구자들이 쉽게 딥 러닝 알고리즘을 구현할 수 있도록 도왔다.
※ 쿠다(CUDA, Compute Unified Device Architecture) : GPU에서 수행하는(병렬 처리) 알고리즘을 C 프로그래밍 언어를 비롯한 산업 표준 언어를 사용하여 작성할 수 있도록 하는 GPGPU 기술
※ 딥러닝(Deep Learning) : 컴퓨터가 알고리즘을 기반으로 학습해서 사람처럼 스스로 인지, 판단하여 데이터를 분석하는 기술
하지만 딥러닝 기술은 아직 주목을 받지 못했다. 이를 뒤집은 은 2012년에 일어났다. 토론토대학의 알렉스 크리제브스키의 슈퍼비전팀이 이미지넷 경진대회에서 우승을 차지하였다. 컴퓨터 비전 코드를 전혀 사용하지 않고 우승을 한 것이다. 그 비결은 딥 러닝을 활용해 자체적으로 이미지를 인식하도록 그들의 컴퓨터를 학습시켰던 것이다.
슈퍼비전팀의 딥러닝 기술은 기계 학습 시간을 수 십일에서 5~6일로 단축시켰으며, 이미지 인식 정확도 80%를 뛰어넘었다. 뿐만 아니라 슈퍼비전팀은 자신의 소스코드를 공개하여 이후 딥러닝의 붐업을 이끌어 갔습니다. 이후에 진행된 이미지넷 대회에서 모든 참가자들은 이제 GPU 기반 딥러닝을 활용하기 시작했다. 딥러닝 기술이 본격적으로 두각을 나타내기 시작한 것이다.
현재는 GPU 기반 병렬 컴퓨팅의 성능은 인공지능(AI) 개발에 있어서 이제 없어서는 안 될 중요한 존재가 되어버렸다.
AI에 HBM 필요한 이유
AI에 HBM이 필요한 이유 : 학습
인공지능의 첫 번째 단계는 학습이다. AI 연구원들은 인공신경망을 구성하고 학습을 위해서 수백만 개 이상의 데이터를 준비한다. 학습 작업은 24시간 내내 GPU를 구동해도 수시간, 수개월이 걸리는 매우 고된 작업이다.
학습 작업을 빠르게 하기 위해서는 학습 데이터가 최대한 연산 장치에 가까이 있어야 한다. 당연히 GPU와 최대한 가까운 곳에 HBM이 위치해야 된다. GPU 회사가 HBM의 큰 고객이 될 수밖에 없는 이유다.
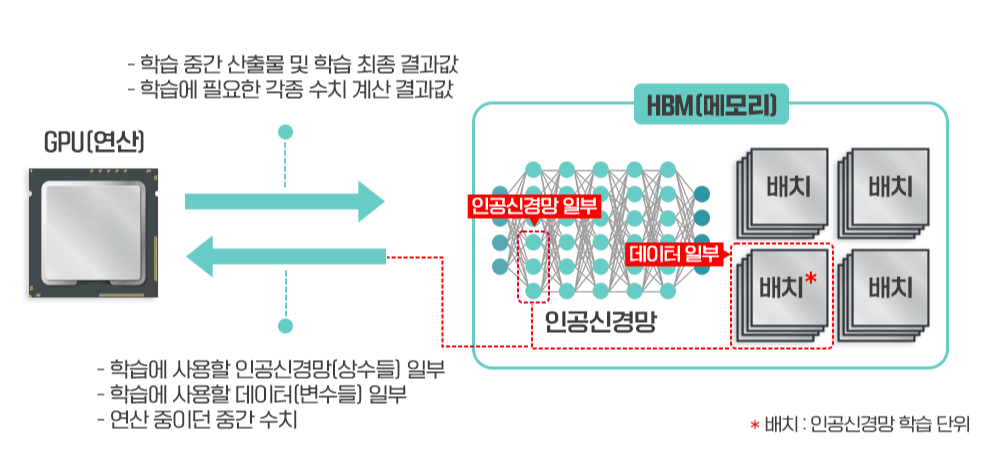
고성능 GPU는 한 번에 처리 가능한 연산량이 매우 크기 때문에 한 번에 많은 데이터가 투입되어야 고성능 GPU가 제 기능을 발휘할 수 있다. 따라서 고성능 GPU 역시 큰 대역폭, 즉 HBM이 필요한 것이다.
AI에 HBM이 필요한 이유 : 추론
HBM은 추론에서도 강력한 힘을 발휘하고 있다. 2023년 오픈 AI가 개발한 챗GPT 등 생성형 AI가 대두하기 시작했는데, 이러한 생성형 AI는 추론에도 매우 큰 메모리가 필요하다.
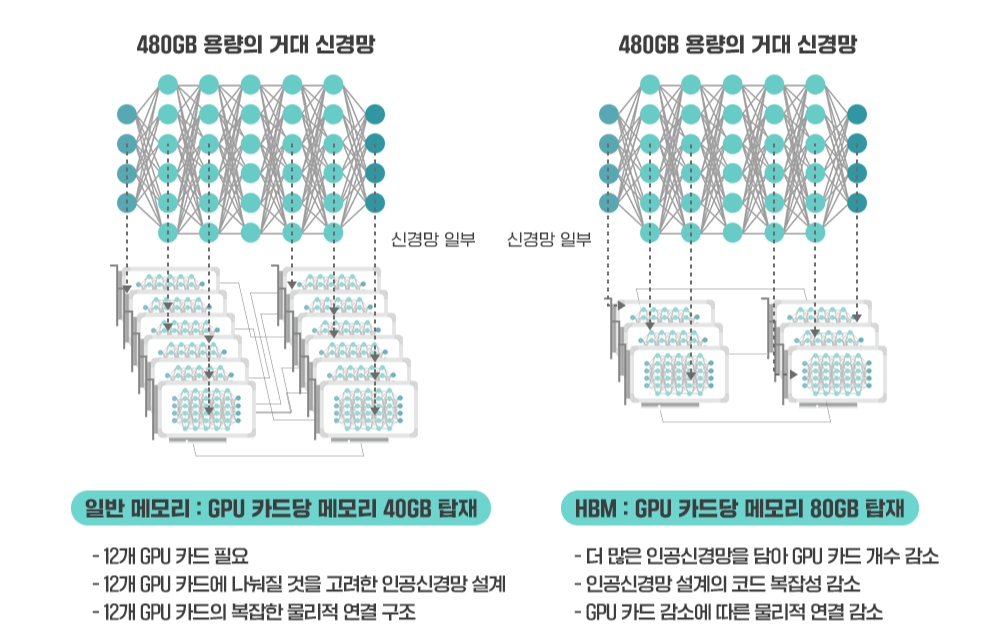
챗GPT는 자료 선택에 따라 320~640GB 정도의 메모리를 사용할 것으로 예상된다. 이는 일반적인 컴퓨터 메모리의 10배 이상인 수치이다. GPU가 이런 큰 용량을 감당해야 하는 것이다.
이러한 대용량 메모리를 GPU에 탑재하기 위해서는 면적당 메모리 집적도가 매우 높아야 한다. 때문에 HBM과 같은 면적 대비 밀도가 높은 칩이 필요한 것이다.
결론
이번 포스팅에서는 HBM이란 무엇인지, 그리고 AI와 GPU에서 HBM이 필요한 이유에 대해서 알아보았다. 세부적인 사항은 전문가의 영역이니 여기까지 하기로 한다.




댓글